

A New York Times beperelte az OpenAI-t és a Microsoft-ot, azt állítva, hogy ChatGPT mesterséges intelligencia rendszerüket a híroldal cikkeinek felhasználásával képezték ki, és ezzel megsértették a szerzői jogokat. A per szerint a vállalatoknak „milliárd dolláros” kártérítési felelősséget kell vállalniuk. A per szerint a New York Times cikkeinek „milliói” kerültek felhasználásra a ChatGPT fejlesztéséhez engedély nélkül, és a rendszer most már versenytársa a hírlapnak megbízható információforrásként.
A vádirat szerint a ChatGPT néha „szó szerinti részleteket” generál a New York Times cikkeiből, amelyeket előfizetés nélkül nem lehet elérni. Ennek eredményeként az olvasók jogtalanul férhetnek hozzá a New York Times tartalmához, kiváltva ezzel a lap előfizetési bevételeinek és a weboldal reklámbevételének csökkenését.
A per továbbá kifogásolja azt is, hogy a Bing keresőmotor eredményeket generál a New York Times tulajdonában lévő oldalakról anélkül, hogy hivatkozna a cikkre vagy hozzáadná a hivatkozási linkeket. Az ügy pikantériáját növeli, hogy a Microsoft több mint 10 milliárd dollárt fektetett be az OpenAI-be.
A per a New York Times sikertelen kísérletéről is beszámol, amikor áprilisban „baráti egyezséget” próbált elérni a Microsofttal és az OpenAI-val a szerzői jogok ügyében. Ez a jogi lépés egy sor hasonló pert követ, amelyek 2023-ban indultak, beleértve a szerzői jogok megsértése miatt indított eljárásokat, valamint az OpenAI és a Microsoft elleni más jogi lépéseket, például a Copilot AI képzése során felhasznált kód engedély nélküli használatával kapcsolatos pert. Ezen ügyek sincsenek még egyelőre lezárva.
A PhoneBazis véleménye
A vádirat több érdekes pontot is megjelöl, az egyik, hogy a ChatGPT 3-as modellje milyen weboldalakról másolt szövegről lett betanítva. Ezek a következők:
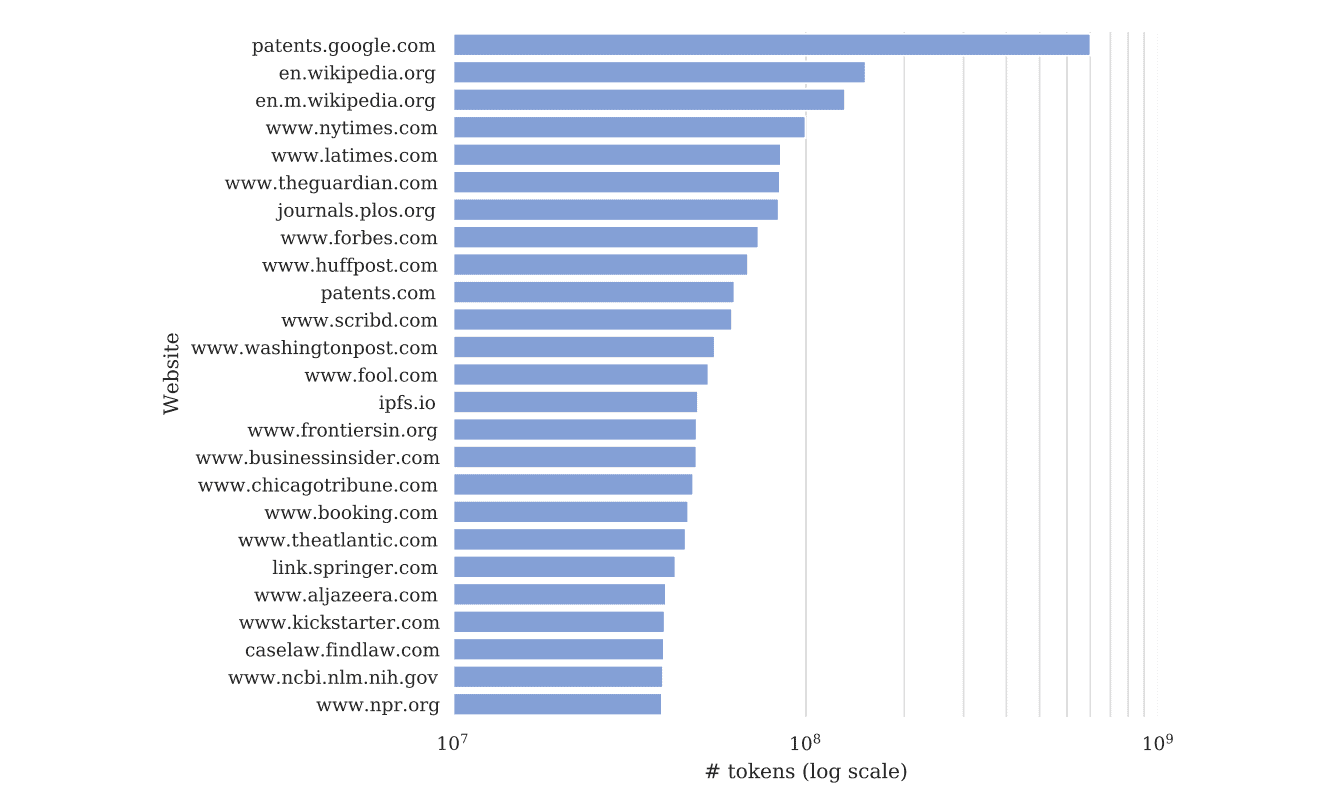
Szerintük a Common Crawl adathalmaz (általános feltérképezés) legalább 16 millió egyedi tartalmi rekordot tartalmaz a The Times News, a Cooking, a Wirecutter és a The Athletic oldalairól, és több mint 66 millió teljes tartalmi rekordot a The Times-ról.
A vádiratban egy 2019-es Pulitzer-díjas alkotásról is említést tesznek, amelyben egy 18 hónapos nyomozás eredményét tárták fel, több mint 600 interjú után. Szerintük a GPT-4 egy kisebb utasítás után ugyanazt a cikket hozta ki eredményül, mint azt, amibe a NY Times újságírói kemény munkával készítettek el.

De ugyanez történt egy 2012-es cikkel is, amiben az Apple és más tech cégek hogyan változtatták meg a globális gazdaságot azzal, hogy kiszervezték a munkáik – gyártósoraik egy részét.
Ahogy a fenti ábrán is láthatjuk a NY Times a Wikipedia után következik a betanítási listán, és az sem kizárt, hogy az olyan népszerű oldalak is csatlakoznának a keresethez, vagy perelnék ezután az OpenAI-t mint a Forbes, az LA Times, a The Guardian vagy a Washington Post.
Felmerül továbbá a kérdés azzal kapcsolatban is, hogy a ChatGPT hogyan fért hozzá a fizetős tartalmakhoz ezeken az oldalakon? Ezzel valószínűleg a szándékosság is könnyebben Sztárjkba fognak-e az újságírók is az AI ellen? A per eredménye biztosan nagy jelentőséggel bír majd, mint a mesterséges intelligencia iparágában, mint a médiában.
A ChatGPT megjelenésével Magyarországon is egyre több szövegíró, újságíró fél attól, hogy lecserélhetővé válik, és ezzel elveszítik keresetüket az ilyen egyszerű szöveggenerálásnak köszönhetően.
Bár mi nem vagyunk jogászok, de valószínűleg hibázott az OpenAI azzal kapcsolatban, hogy nem kért előre engedélyt a médiaorgánumoktól a szöveges tartalmaikon való betanulással kapcsolatban.
Te mit gondolsz az esetről? Megtiltanád az OpenAI-nak és más hasonló nyelvi modelleknek, hogy a szöveges tartalmaidon tanuljanak be?
Ez is érdekelhet:
- A TikTok az iPhone felhasználók jelszavára utazik?
- Az Intel 25 milliárd dolláros beruházást tervez Izraelben


